


作者 | 常盛
「我认为世界上每一家企业,每一家软件公司,都需要一个 Agent 系统,一个 Agent 战略!」
在最近举办的 GTC 2026 大会上,当英伟达 CEO 黄仁勋抛出这句话时,很多人第一反应是:Agent 正在成为 AI 行业的新共识。
英伟达在大会上也把 Agent 系统放到了非常靠前的位置,强调软件、推理和智能体正在一起重塑企业的技术框架。

如果把这个判断放到辅助驾驶行业来看,意思其实更直接:当整个 AI 行业都在换代,智驾也不可能继续沿用旧方法,只靠修修补补往前走。
过去两年,辅助驾驶行业表面上很热闹。无图、端到端、VLA、世界模型、强化学习……一时间,行业内热词不断涌现,技术迭代不断加快。
随着高精地图不再是前提,城区 NOA 开始大规模开城,整个行业都像是迈过了一道门槛。
也正是在这样的背景下,一些公司开始不再满足于修补现有体系,而是尝试从底层重塑系统逻辑。
在今年的 GTC 上,元戎启行给出的,就是这样一种更彻底的解法。他们没有再围绕局部优化做文章,而是提出用一套统一的 Foundation Model(基座模型),同时承担感知、理解、推理与决策的能力。
换句话说,不再是多个模块各自为战,而是让系统拥有一个可以持续进化的「统一大脑」,这个思路听起来甚至带着一点理想主义色彩。
但真正关键的问题在于:为什么直到现在,行业才开始认真讨论这件事?
01
停滞的 18 个月:
端到端之后,再无真突破
过去几年,如果把热闹的概念堆叠剥开,把厂商宣传的包装去掉,你会发现一个尴尬的事实:智驾的进步速度,并没有跟上热词迭代的速度。
对此,元戎启行 CEO 周光曾经在 2025 年广州车展期间点破过这层窗户纸。当时有厂商宣称「两年推出三代技术」,他的回应很直接:
一两个月就有变化的,多是基于规则的修补,大的技术迭代一年一次已属不错。他举了特斯拉的例子——从 V12 到 V15,基本保持着一年一次的实质性迭代频率。
这句话的潜台词是:行业里很多所谓的「技术突破」,其实是营销口径的突破,不是模型能力的突破。为什么迭代这么难?因为智驾行业的底层逻辑,正在发生一场无声的断裂。
时间拨回到 2024 年初。
那时候,整个行业都在为「无图端到端」欢呼。高精地图这个曾经被视为自动驾驶「拐杖」的东西,终于被甩掉了。华为说「全国都能开」,小鹏说「不限城市」,理想说「全场景」。
一时间,各家都在比拼开城数量,仿佛去掉地图,智驾就能一夜间飞入寻常百姓家。
现在回头看,2024 年初那场「无图运动」,竟然是智驾行业过去 18 个月里最后一次真正的范式突破。
地平线副总裁苏箐在 2025 年底的一次发言中,点破了这个尴尬。他说,FSD V12 的发布确实是分水岭,它证实了端到端路径的可行性。
但他紧接着补了一句:未来三年,自动驾驶行业将告别范式迭代的狂飙,进入极致优化的「苦日子」。

「苦日子」这三个字,翻译成大白话就是:大的突破没了,剩下的都是修修补补。
2024 年到 2025 年,行业内热词没断过:端到端、VLA、世界模型、强化学习。但如果把时间线拉长来看,你会发现一个扎心的事实:
从体验层面,过去 18 个月以来,其实整个行业没有「根本性」的提升。
不信可以问一个普通用户:
2025 年底的城市 NOA,比 2024 年初好用多少?他大概率答不上来。也许在某些场景下更顺滑了,但遇到施工改道、遇到不规则障碍物、遇到需要读文字牌的复杂路口,该接管还是得接管。
业内有个共识:数据规模确实在涨,但数据的质量没有跟上。某头部智驾供应商内部做过统计,他们采集的上亿公里数据中,真正有价值的长尾场景占比不到 10%。剩下的 90%,都是在高速、环路、通畅城市道路上的重复劳动。
这就像一个人在跑步机上拼命跑,跑了一年,汗流了不少,但抬头一看,还在原地。
懂车帝在 2025 年 7 月做的那场「突袭体检」,把这种尴尬摆到了台面上。
36 款主流车型,15 个高危场景,综合高速场景通过率仅 24%。「消失的前车」场景,超过 70% 的碰撞率。
这些被测试的车,每一辆的发布会都开得轰轰烈烈,每一家的宣传册上都写满了「遥遥领先」。
但把包装纸撕掉,把 PPT 合上,回到真实道路上,它们还是被那块「禁止通行」的指示牌难住了。
苏箐说得更狠,「当前深度学习已显露天花板迹象,AGI 基础理论暂无突破信号。」翻译一下就是:别指望明天就有新魔法,接下来拼的是耐力。
02
100 亿英里的门槛:
为什么数据越多车越笨?
正当行业还在争论「端到端是不是终极答案」时,特斯拉已经跑到了另一个量级。
2026 年 2 月,特斯拉宣布 FSD 累计行驶里程突破 84 亿英里。开年头 50 天,新增 10 亿英里。
按照这个速度,马斯克设定的 100 亿英里目标,今年就能撞线。
这个数字意味着什么?意味着特斯拉每小时收集的数据量,比别人一年加起来还多;意味着全球有超过 250 万辆特斯拉,每天都在给 FSD 当「陪练」;意味着当别的厂商还在为数据采集车跑哪条路发愁时,特斯拉已经用真实世界建了一座训练场。
但更值得玩味的是另一个数据:MPCI——城市里程与关键接管之间的比值。
根据第三方 FSD 社区追踪器的数据,FSD V14.1 在 2025 年 10 月达到峰值时,MPCI 是 4109 英里。也就是说,平均每行驶 4109 英里城市道路,才需要一次关键接管。
4109 英里是什么概念?
约等于 6613 公里。从北京开到乌鲁木齐,往返一趟,只需要接管一次。
而国内优秀的城市 NOA 水平,还在几十到百公里级别。这个差距,不是用我们更懂中国路况能填平的。
更让国内厂商焦虑的是,这个差距可能还在拉大。特斯拉的规模效应正在形成正循环:
更多车跑→更多数据→更好模型→更多车愿意买 FSD→更多车跑。这个飞轮一旦转起来,后来者连追的机会都没有。
周光看得明白。他在 2025 年说过一句话:「几万台和十几万台没有本质区别,可能到一百万台才会有区别。」
为什么是 100 万?因为只有到了这个规模,数据才不再是数字,而是「复利」。
如果只有几十万台车,每天产生的数据量不足以覆盖足够多的长尾场景,模型迭代就像挤牙膏。只有过了百万门槛,数据才能形成模型优化、安全升级、规模扩大的正循环。

但这里有个更大的陷阱:如果没有统一的模型基座去整合这些数据,100 亿英里也只是垃圾。
很多供应商走的是另一条路:接十几个小项目,每个项目因为硬件差异——摄像头位置不同、雷达性能不同、算力平台不同——都得把模型拆开、微调、适配。
结果就是,数据被分割在不同的子模型里,参数共享效率低,深度认知能力根本形不成。
从表面上看,好像项目多、覆盖广,实际上每个车型的安全标准都不一样,极端场景下极易出问题。
这就解释了为什么数据堆了这么多,车还是变「笨」了。不是因为数据不够,而是因为数据没有流进同一个大脑。
03
行业缺的不是「子系统」,
而是「统一大脑」
可以说,今天的辅助驾驶,不缺数据,也不缺模型,缺的是一套能把数据变成能力的「统一大脑」。
如果把今年 GTC 2026 各家辅助驾驶的内容再往回看一遍,一个很明显的变化是:大家已经不太满足于只讲某一个模块做得多强了,而更愿意讲系统级能力。
GTC 上,理想讲「单一 Transformer」、小米讲「同一端到端网络」、Wayve 讲「一套通用模型」、吉利讲「全域 AI 2.0」、元戎讲「Foundation Model(基座模型)」。
这说明行业已经逐渐形成共识:下一阶段的辅助驾驶竞争,不是谁局部功能更炫,而是谁先拥有一套真正能持续成长的统一大脑。
其中,元戎提出的 Foundation Model 也成为这场讨论的焦点。很多人第一次听到「基座模型」,容易把它理解成一个更大的模型,或者另一个新热词。但如果只这么理解,其实低估了这件事。
事实上,基座模型并不是一个新鲜事物,此前,Waymo 也曾经提出过自己的基座模型。
对于辅助驾驶而言,基座模型最重要的意义,不是「模型变大」,而是研发范式在变。
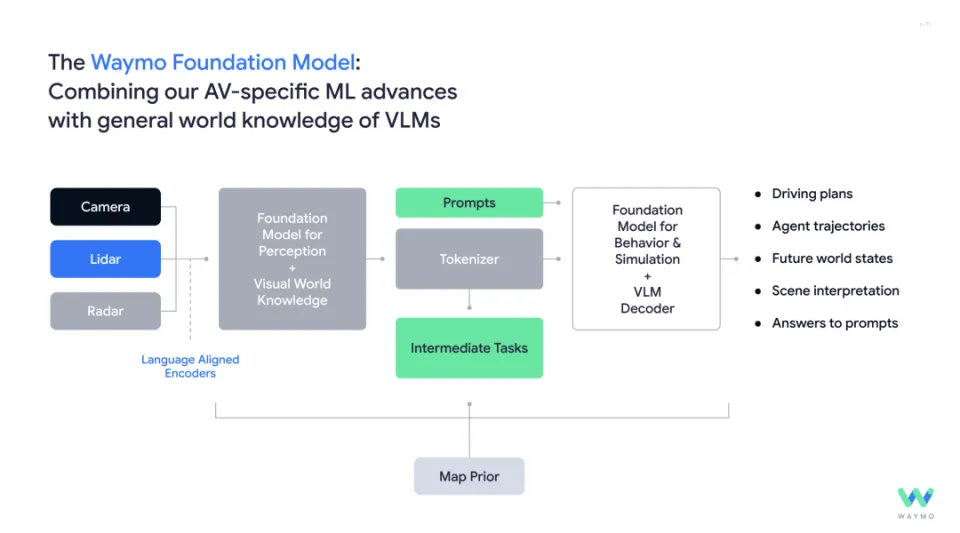
过去的辅助驾驶,数据闭环的流程其实已经非常成熟,但许多关键环节仍然高度依赖人工参与。
例如,在问题发现阶段,往往仍然需要人工去分析接管事件或异常行为;在根因分析和场景分类阶段,也常常需要人工进行经验判断。
而引入基座模型之后,则是用一个统一的模型,同时承担驾驶、分析、评估多种角色,让系统不是「东拼西凑地完成驾驶」,而是像一个整体那样去理解和行动。
这个变化,表面看是架构变化,本质上其实是在回答一个更根本的问题:辅助驾驶到底是靠不断堆人工、堆工程细节往前走,还是让系统统一驱动进化?
元戎显然押注了后者。因为行业发展到今天,大家已经越来越清楚:
如果系统没有形成更强的世界认知,只靠不断补策略、补规则、补场景,最终只能得到一个越来越复杂、越来越重、越来越难持续进化的系统。
对此,元戎启行 CTO 曹通易给出了一组数据对比:原先一套的数据闭环跑下来,耗时超过 5 天,100 多个小时;但在引入 Foundation Model 之后,数据闭环的效率缩短到 12 小时。

也正因为如此,元戎启行选择把视线从继续修补旧体系,转向重塑辅助驾驶的能力体系。
如果这条路能够跑通,那么辅助驾驶下一阶段的变化,就是从底层开始发生质变:车会越来越懂路,越来越懂人,也越来越接近一个「老司机」该有的判断力。
说到底,今天行业最缺的,已经不是又一个更响亮的热词,而是一种能把规模变成能力、把数据变成复利、把系统变成整体的新方法。
而这,或许才是无图之后,智驾真正的新起点。
恒汇证券app提示:文章来自网络,不代表本站观点。


